Bancos de Dados são os principais sistemas que encontramos em empresas. Imagine você criar um mini sistema de banco de dados concorrente ao da Oracle! Neste projeto iremos construir um esboço desse sistema , mostrando de forma simplificada o funcionamento interno de um banco de dados e permitindo a você construir o seu próprio SBD.
Banco de Dados
Um Sistema de Gerenciamento de Banco de Dados (SGBD) – do inglês Data Base Management System (DBMS) – é o conjunto de programas de computador (softwares) responsáveis pelo gerenciamento de um banco de dados. Seu principal objetivo é retirar da aplicação cliente a responsabilidade de gerenciar o acesso, a manipulação e a organização dos dados. – Wikipédia
Índice
- 1 Organização e Estrutura de Dados do SGBD
- 1.1 Esquema
- 1.2 Tabela
- 1.3 Tupla
- 1.4 Desenvolvimento do sistema
- 1.5 Desenvolvimento da estrutura de dados: índice hash
- 1.6 Definição de tipos de variáveis para as partes do banco de dados
- 1.7 Implementar funções
- 1.7.1 Criar nova tabela
- 1.7.2 Função para pesquisar tabela
- 1.7.3 Listar tabelas
- 1.7.4 Remover tabela
- 1.7.5 Inserir tupla
- 1.7.6 Remover tupla de tabela
- 1.7.7 Pesquisar por tuplas em tabela
- 1.8 Interação com Usuário
- 2 Versão 1: Criando uma linguagem SQL simplificada
Organização e Estrutura de Dados do SGBD
Um banco de dados tradicional é composto por: esquema, tabela e tupla.
 Esquema
Esquema
Um esquema (schema) é representado por uma coleção de vários objetos de um ou mais usuários do banco de dados. Esses objetos podem ser, por exemplo, tabelas, seqüências e índices. Em um banco de dados podem existir vários esquemas.
 Tabela
Tabela
Uma tabela é a unidade básica de armazenamento em um banco de dados. Sem tabelas, um banco de dados não tem valor para uma empresa pois é aonde armazena-se dados. Podemos imaginar uma tabela como sendo um documento de planilha financeira, em que temos vários colunas e linhas. Nessas linhas e colunas temos vários informações de clientes, tais como, nomes, telefones, endereços, CPF e outros. Independente do tipo de tabela, seus dados são armazenados em linhas e colunas.
Tupla

Desenvolvimento do sistema
O desenvolvimento do seu sistema de banco de dados vai acontecer de acordo com as seguintes etapas:
- Desenvolvimento da estrutura de dados: criação de índice hash para busca e armazenamento de dados
- Definição de tipos de variáveis para as partes do banco de dados
- Implementar funções de inserir, pesquisar e remover em esquemas e tabelas
Desenvolvimento da estrutura de dados: índice hash
A estrutura que usaremos para guardar e buscar dados é o índice hash. Faremos aqui uma explicação simplificada, mas você pode acessar as aulas sobreíndice “hash” do site Programação Descomplicada.
Essa índice usa uma função hash, em português, espalhamento, para atribuir uma posição para cada elemento sendo inserido em um vetor.
Cada elemento é identificado por sua chave. A função hash faz um cálculo usando a chave para encontrar a posição correta no array. No caso do nosso banco de dados, a chave de cada tabela é referente ao seu nome.
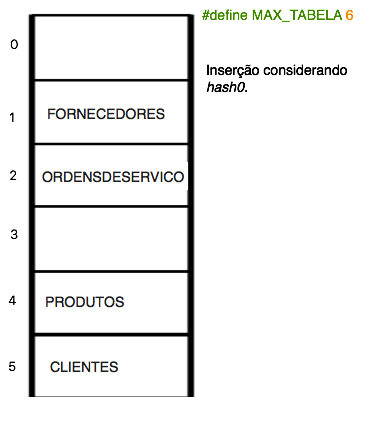
Nossa função hash deve calcular a partir de uma chave, que é o nome da tabela, e atribuí-lo a uma variável de valor inteiro que identifica a posição que ela deve ser inserida. Essa variável será chamada de “pos”, em referência a posição que ela identifica. pos é um inteiro calculado a partir da soma dos valores inteiros que cada caracter que compõe o nome da tabela.
Uma ideia para a construção de uma função hash para tabelas é calcular o módulo do MAX_TABELAS pela soma do valor de cada caractere da tabela. Defina a constante MAX_TABELAS usando um #define MAX_TABELAS … . A função pode ser feita da seguinte forma:
int hash0(char *nome_tabela){
int soma = 0,i = 0;
while (nome_tabela[i] != '\0'){
soma = (soma + nome_tabela[i])%MAX_TABELAS;
i++;
}
return soma&0x7fffffff;
}
OBS: O 0x7fffffff é usado para representar 0111111111111…, o & tem a mesma função do “and” lógico. Essa operação é necessária pois quando a soma passar do maior número que pode ser guardado na variável, o valor dela fica negativo, logo, “soma&0x7fffffff” resulta em um “and” bit a bit, onde, apenas o primeiro bit vai se tornar zero. Evitando dessa forma o valor soma ser negativo.
A figura ao lado mostra como os nomes das tabelas “CLIENTES”, “FORNECEDORES”, “PRODUTOS”, “ORDENSSDESERVICO” ficariam organizadas em um vetor do índice “hash” sendo #define MAX_TABELAS 6.
Desenvolvimento de função de inserção em índice “hash” :
A inserção de novos elementos em um índice hash é feita pela função put() que tem o seguinte protótipo:
- put_tabela(Esquema *esquema_relacional, Tabela elemento_tabela) – ‘no caso do índice hash para tabelas’
Caso existam duas tabelas com a mesma chave verificamos se possuem o mesmo nome. Nessa situação dizemos que houve uma colisão. Colisões são problemáticas e é importante saber como tratar colisões.
Ao usar a função put(), se houver colisões:
Não inserimos e exibimos uma mensagem para o usuário informando que a inserção foi bem sucedida; caso contrário, inserimos na posição seguinte no vetor. Se estiver na última posição é necessário voltar à posição 0 do vetor. Se não houver mais espaço, é necessário avisar o usuário.

Observe que, antes usar a índice “hash” é necessária alguma preparação da estrutura de dados. Por exemplo, para identificar os espaços vazios podemos fazer uma função prepara_esquema que atribui o valor 0 ao atributo quantidade_tabela e, por convenção, coloca o valor false na keytable de cada tabela do esquema. Desse modo só iremos inserir na dada posição se keytable != -1.
- put_tupla(Tabela *conjunto_de_tabelas, Tupla elemento_tupla) – ‘no caso do índice hash para tuplas’
Para ‘tupla’ o funcionamento de ‘put’ é similar, inclusive no tratamento de colisões. Lembrando que cada tupla contém uma chave única denominada primary key.
Desenvolvimento de função de busca em índice “hash” :
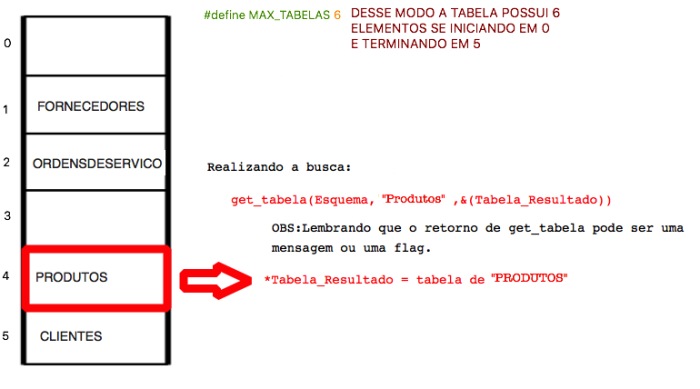
A busca de novos elementos em uma índice “hash” é feita pela função get() que tem o seguinte protótipo:
- get_tabela(Esquema esquema_relacional, char *nome_tabela, Tabela *elemento_tabela)
A função get_tabela verifica a existência, no esquema_relacional, de uma tabela que possui o nome dado pela string nome_tabela. Através da função hash0é encontrada a posição da tabela dada por nome_tabela no vetor de tabelas. Se essa posição estiver ocupada e o elemento possuir o mesmo nome, atribuimos o elemento encontrado ao parâmetro elemento_tabela e o exibimos; Caso a posição esteja ocupada e o elemento não possuir o mesmo nome retornamos uma mensagem de erro para usuário; caso a posição esteja vazia, retornamos uma mensagem relatando que a tabela não existe.
- get_tupla(Tabela conjunto_de_tabelas, int chave_tupla, Tupla *elemento_tupla)
Basicamente, a função get_tupla possui o mesmo funcionamento que get_tabela, entretanto o que devemos considerar um vetor de tuplas e não de tabelas.
Definição de tipos de variáveis para as partes do banco de dados
Esquema
O esquema é composto por um vetor de tabelas e um atributo inteiro que registra a quantidade de tabelas do esquema. Sendo o esquema definido pela struct abaixo:
typedef struct esquema {
int quantidade_tabela;
struct tabela Tabela[MAX_TABELAS];
} Esquema;
Lembrando que você deve definir uma quantidade máxima de tabelas no esquema. Podemos definir isso utilizando um define por um valor MAX_TABELAS. Por exemplo:
#define MAX_TABELAS 100
Tabela
Uma tabela é composta por um vetor de tuplas, um vetor de caracteres nome, uma chave inteira (obtida por uma função hash a partir do seu nome) e um atributo inteiro quantidade que registra a quantidade de duplas. Sendo a tabela definida pela struct abaixo:
typedef struct tabela{
int keytable;
int quantidade_tupla;
char nome_tabela[20];
struct tupla conjunto_de_tuplas[MAX_TUPLAS];
}Tabela;
Sendo MAX_TUPLAS uma definição, como no item anterior, de uma quantidade de tuplas. Por exemplo:
#define MAX_TUPLAS 60
O vetor conjunto_de_tuplas[MAX_TUPLAS] será usado na forma da estrutura de dados de uma índice hash da referida tabela do banco de dados.
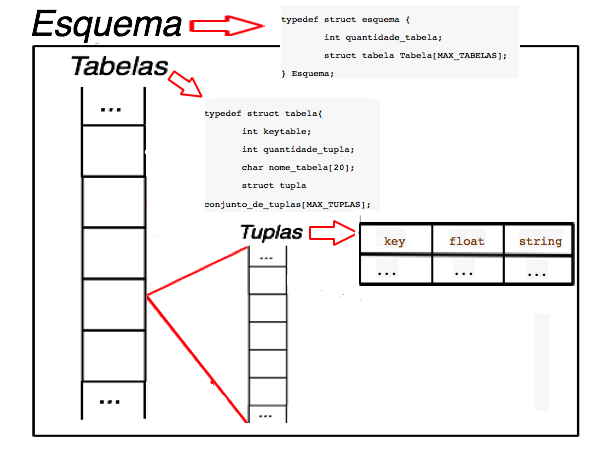
Tupla
A nossa tupla simplificada pode ter uma chave inteira key, um número real f ou um vetor de caracteres string, ou um de cada. A estrutura que representa esses campos é definida pela struct abaixo:
typedef struct tupla {
int chave;
double ponto_flutuante;
char string[MAX_STRING];
}Tupla;
A constante MAX_STRING é também uma definição do tamanho da variável string. Onde pode ser definida como:
#define MAX_STRING 200
Implementar funções
Como a estrutura e organização de dados já foram definidas devemos agora definir as funções que irão compor nosso SGBD. Nosso banco de dados terá as seguintes operações em tabelas:
- Criar nova tabela
- Remover tabela
- Listar tabelas
e as seguintes operações de tuplas em tabelas:
- Inserir nova tupla em tabela
- Remover tupla de tabela
- Pesquisar por tuplas em tabela
Criar nova tabela
A criação de tabelas envolve a inserção de dados mo índice “hash”. Antes de criar uma nova tabela devemos primeiramente verificar se o esquema possui espaço disponível para isso verificamos a variável que registra a quantidade de tabelas no esquema. Após termos certeza que tem espaço para colocar um nova tabela podemos inserir utilizando a função put_tabela.
Função para pesquisar tabela
A função de pesquisa é composta pela função get_tabela. A pesquisa é realizada no índice hash tal qual a descrição de get_tabela.
Listar tabelas
A pesquisa considera o valor chave dado pela função hash a partir do nome da tabela pesquisada. Agora devemos considerar também que caso a tabela não esteja na posição dada por hash ela pode estar em outra posição. Desse modo devemos fazer um laço que percorre o vetor de tabelas procurando a tabela com o nome pesquisado. Caso a tabela seja encontrada podemos retornar a própria tabela,se você não passou uma tabela como parâmetro, ou atribuir a tabela a variável parâmetro, que foi passada por referência.
Remover tabela
Para remover uma tabela temos que fazer algumas considerações:
- Se a esquema possui tabelas
- Se a tabela existe ou se foi removida
Para verificar se o esquema possui tabelas devemos verificar a variável de controle quantidade_tabelas. Se a quantidade de tabelas for zero, retornamos uma indicação de falha ou fracasso; caso contrário, continuamos com as próximas verificações. A próxima verificação a ser feita é utilizando a chave obtida a partir da função hash0, onde verificamos na posição do vetor correspondente ao valor da chave: caso seja a tabela que se deseja remover, atribuímos -1 a chave da tabela e retornamos alguma confirmação (pode ser um valor inteiro ou uma mensagem); caso contrário percorremos todo o vetor de tabelas a partir da posição seguinte. Se ao fim da busca pelo vetor a tabela for encontrada, colocamos -1 na chave e retornamos alguma confirmação; caso contrário retornamos alguma mensagem de erro.
Inserir tupla
Assim como a função para inserir tabela, a função para inserir uma tupla é com posta por um put. O put_tupla possui funcionamento semelhante aoput_tabela, com a única diferença de que a chave da tupla é um inteiro e não originária de uma string como a chave de uma tabela.
Remover tupla de tabela
O primeiro passo para remover uma tupla é verificar se existem tuplas a serem removidas. Essa verificação é feita verificando se a quantidade de tuplas é maior que zero, ou seja, quantidade_tupla > 0. Se a quantidade seja menor que zero, retornamos uma mensagem de erro; caso contrário será executada a próxima verificação. Agora devemos verificar se da posição dada pela função hash contém a tupla que será removida. Se a tupla estiver na dada posição, atribuímos -1 a chave da tupla; Caso contrário percorremos o vetor a partir da posição dada por hash verificando todo o vetor até que retornemos a mesma posição. Se a tupla for encontrada atribuímos -1 a chave da tupla e retornamos uma mensagem de confirmação, se não, retornamos uma mensagem de erro.
Pesquisar por tuplas em tabela
Para pesquisar as tuplas em uma tabela utilizaremos a função get tupla. get_tupla possui funcionamento semelhante a get_tabela ,mas como foi anteriormente, a chave da tupla é dada por um inteiro.
Interação com Usuário
A interface com o usuário deve possuir dois menus:
- Menu esquema: compreende a inserção, deleção e pesquisa de tabelas.
- Menu tabela: compreende a inserção, deleção e pesquisa de tuplas.

OBS: A biblioteca gráfica deve ser escolhida pelo programador, onde, dentre as bibliotecas mais conhecidas temos NCURSES, Allegro e GTK.
Versão 1: Criando uma linguagem SQL simplificada
CREATE TABLE, INSERT INTO, SELECT FROM, DELETE, DROP
